
In 2026, building on a company project I worked on in 2025 and its associated call‑on‑support system, I developed a small proof‑of‑concept that creates and queries a RAG (Retrieval‑Augmented Generation) index using LangChain (with LlamaIndex as an alternative option), FAISS as the vector store, and OpenAI for embeddings and natural‑language generation.
The solution was designed and implemented but never deployed to production, as it was later merged and incorporated into a larger, company‑wide custom Agents Orchestrator.
An alternative approach—based on LlamaIndex and an on‑premises custom model—was also evaluated to provide a lighter RAG pipeline and to avoid sending sensitive information to external LLM engines. The following model were tested: Llama3.1 and Mistral.
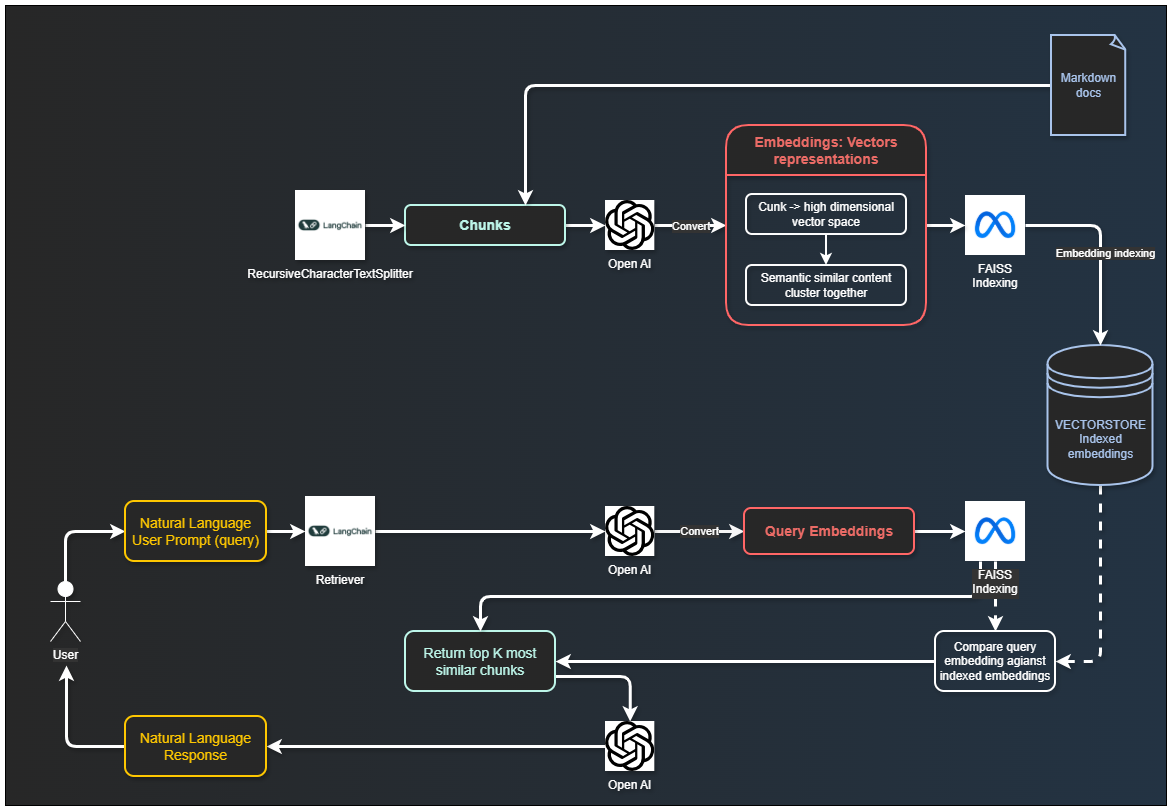
Architecture overview (diagram): custom RAG implementation using OpenAI as the embedder and LLM, LangChain for orchestration and document chunking, and FAISS as the vector database.
GitHub repository: https://github.com/michelesalvucci/custom-rag
Structure
As mentioned, semantic search relies on embeddings generated with OpenAI’s text-embedding-3-small model, while responses are produced using OpenAI chat models (by default, gpt-4o-mini).
The setup consists of two main scripts: one for building the index and another for handling queries. An interactive mode can also be implemented, allowing users to ask follow-up questions without needing to repeat the context. This mode supports the following commands:
- Type
resetto clear the conversation history - Type
exit,quit, orqto terminate the session
Several parameters are configurable:
- Switch the embedding model (e.g.,
text-embedding-3-large) - Select a different LLM using
--model(e.g.,gpt-4.1,gpt-4o-mini) - Control retrieval depth with
-k/--top-k - Adjust generation behavior via
--temperature
Temperature (--temperature)
temperature controls the level of variability (randomness) in the model's response generation:
0.0: more deterministic and consistent output (preferred for technical/documentation Q&A)0.2 - 0.5: balance between accuracy and flexibility> 0.7: more creative and less predictable output
In practice, it does not change document retrieval from the vector index, but only how the model formulates the final response based on the retrieved context.
How does it work
Document Loading
Documents are loaded from files or folders using LangChain loaders:DirectoryLoader for directories and TextLoader for single files.
This allows indexing mixed sources in one run.
Chunking (LangChain)
Chunking is the process of breaking down documents into smaller, coherent pieces that can be efficiently processed by language models. This is essential because LLMs cannot process entire projects at once.
It reduces input size for LLM processing, allows passing only relevant document sections, and improves response accuracy while reducing API costs.
This project uses a two-step split strategy:
MarkdownHeaderTextSplitterto split by Markdown sections (#to######)RecursiveCharacterTextSplitterfor final chunk sizing (chunk_size=700,chunk_overlap=150)
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=[
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
("####", "Header 4"),
("#####", "Header 5"),
("######", "Header 6"),
],
return_each_line=False
)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=700, chunk_overlap=150)Section Hierarchy Preservation
Hierarchy between sections is preserved during indexing.
Instead of concatenating all documents and splitting once, each source document is split independently. This prevents losing file boundaries and keeps subsection relationships consistent within the same file.
For each markdown section, the indexer stores hierarchy metadata:
header_path: full path likeAuth > OAuth > Refresh Tokenheader_level: depth in the hierarchy (1..6)section_id: stable identifier of the current sectionparent_section_id: stable identifier of the direct parent section (orNonefor top-level)root_header: first-level section namesource: original file path
When a section is further split into character chunks, each chunk keeps the same section metadata plus:
chunk_in_section: chunk order inside the same section
This allows retrieval logic to link a subsection back to its father section (via parent_section_id) and to group sibling chunks by section (section_id).
Embedding (OpenAI)
Embedding is the transformation of text or code into numerical vectors that represent semantic meaning. Each chunk is converted into a high-dimensional vector space where semantically similar content clusters together.
Example: "AuthService handles login" → [0.021, -0.44, 0.98, ...]
Implementation: OpenAI Embedding API (text-embedding-3-small model in this project)
Vector Index (FAISS via LangChain)
A Vector Index is an optimized data structure that stores embeddings and enables rapid similarity searches. It is not an AI system but rather an efficient indexing mechanism for quick retrieval.
It stores all document embeddings for fast access, enables millisecond-level search across hundreds or thousands of chunks and replaces inefficient one-to-one chunk comparison.
Implementation: LangChain FAISS.from_documents(...), persisted locally with save_local("faiss_index").
vectorstore = FAISS.from_documents(docs, embeddings)
vectorstore.save_local("faiss_index")Semantic Retrieval (LangChain Retriever)
Semantic retrieval finds the most semantically similar chunks to a given query, rather than relying on keyword matching. It works even when query uses different terminology than source code.
It converts user query to embedding using OpenAI, compare query embedding against indexed embeddings and return top-K most similar chunks.
FAISS retriever with configurable top-K (--top-k, default 3).
retriever = vectorstore.as_retriever(search_kwargs={"k": top_k})Conversation Memory
Interactive mode keeps an in-memory history of previous user/assistant turns and injects recent turns into the prompt, allowing for rollow-up questions without repeating context, reference to previous answers and multi-turn conversations about the codebase.
Example conversation (real case):
You: dove è implementata angrafica gestori?
Assistant: L'anagrafica gestori è implementata nel controller "OutletManagersController" e nel servizio "CustomerService"s
You: che microservizio è?
Assistant: Si trova nel microservizio "outlets".Language Model (OpenAI)
The final component: a generative language model that synthesizes retrieved chunks into coherent, natural language responses. The LLM reads contextual chunks and generates explanations, reasoning, and answers. It synthesizes and explains retrieved information, provides natural language responses to user queries and applies reasoning across multiple chunks.
Bedrock integration
In a future iteration, AWS Bedrock could be used to host the solution in the cloud. For instance, OpenAI embeddings may be replaced with BedrockEmbeddings from the langchain library, allowing to specify which foundation model to use on Bedrock (e.g., Anthropic Claude).
import boto3
from langchain.llms import Bedrock
# Initialize Bedrock client
client = boto3.client("bedrock-runtime")
# Define model configuration
model_kwargs = {
"max_tokens_to_sample": 512,
"temperature": 0.1,
"top_p": 1,
}
# Specify model ID (Claude Instant)
model_id = "anthropic.claude-instant-v1"
# Initialize LLM
llm = Bedrock(
model_id=model_id,
client=client,
model_kwargs=model_kwargs,
)Streamlit integration
Streamlit could be used to build and render a web application for chat interactions with the RAG, leveraging Python directly.
from langchain_community.chat_message_histories import StreamlitChatMessageHistory
st.set_page_config(page_title="Custom RAG", page_icon="<>")
st.title("Custom RAG") @st.cache_resource decorator to not rerun the entire Python file from top to bottom and cache the LLM configuration.
msgs = StreamlitChatMessageHistory(key='langchain_messages') # to keep the messages in memory
if len(msgs.messages) == 0:
msgs.add_ai_message("How can I help you")To render current messages:
for msg in msg.messages:
st.chat_message(msg.type).write(msg.content)And then, when the user inputs a new prompt, generate and draw a new response:
if prompt := st.chat_input():
st.chat_message("human").write(prompt)
# retrieve relevant documents using a similarity search
docs = vectorstore_faiss.similarity_search_with_score(prompt)
info = ""
for doc in docs:
info += doc[0].page_content + '\n'
output = question_chain.invoke({"input": prompt, "info": info}) ## LLMChain object with the model, prompt and output_key defined
msgs.add_user_message(prompt)
msgs.add_ai_message(output)
st.chat_message("ai").write(ouput["answer"])To run Streamlit:
streamlit run python_script.pywill be served locally to be opened on a browser, for example:
Network URL: http://172.16.5.4:8501Further cloud integration
The developed RAG can be further integrated by replacing local vector store with a persistent vector store hosted on cloud using Kendra or Open Search. Morover, Bedrock Agents may be employed to automate inquiry of databases or documentations on the cloud.